
A Beginner’s Guide to Generative Adversarial Networks
Published:
Read this to gain some intuition on how generative adversarial networks solve problems.
A Beginner’s Guide to Generative Adversarial Networks
Note: This article assumes that you have some knowledge of machine learning fundamentals
The way GANs learn is quite interesting, and unique to that of other traditional supervised methods. In a traditional supervised learning objective we have access to the true labels (i.e a class for classification taks, or a score for regression tasks). Therefore, when we make a prediction with our model we have a direct way of assessing how accurate our prediction is: for example in a regression task we could just take the distance between our predictions and their associated true values. This is how we train supervised models. We punish the model when the distance between its predictions and reality are high, and reward it when that distance is low - ushering it towards the minimal distance. With unsupervised methods we can no longer measure distance between paired samples, instead we attempt to minimize the distance between the model prediction and real sample distributions. This idea is depicted in the figure below:
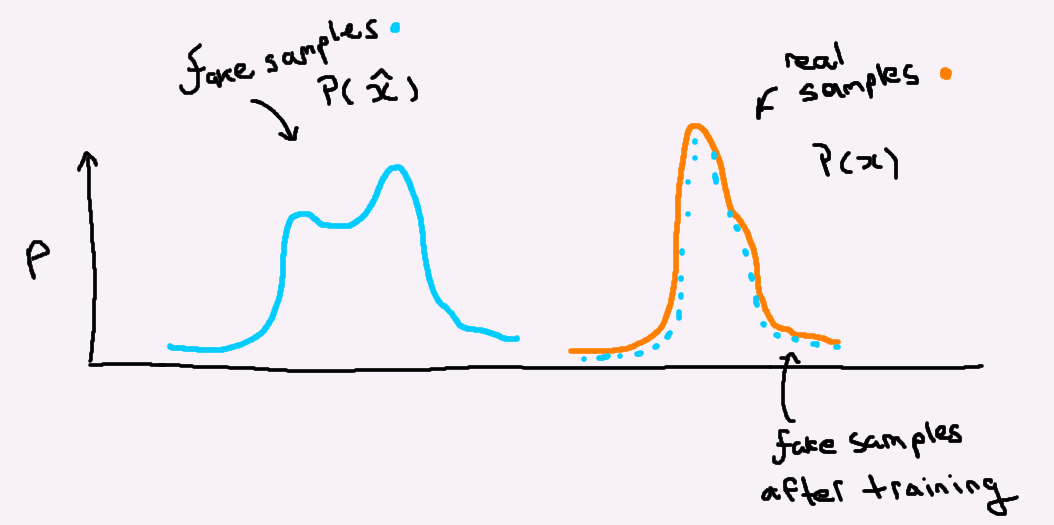
GANs are an unsupervised method. We don’t have paired data like we normally do in supervised learning. What this means is that the model isn’t provided with labels, so it only has access to features. These networks consist of two players: a generator and a discriminator. The objective of the generator is to generate samples indistinguishable from the true distribution of images. The objective of the discriminator is to take those samples generated by the generator and compare them to real samples, and ideally tell the difference between the two. I’ll lay out a situation to hopefully help make this more clear. In the following I’ll refer to the discriminator as the teacher, and the generator as the student.

Consider this situation: let’s say I want to train somebody to draw trees. Let’s call the person drawing these trees the student. I also pull in somebody else to act as a teacher. Let’s say I have access to a large amount of tree images, everything from coniferous trees to bonsai trees. I start by giving a few of these images at a time to the teacher. The student doesn’t have direct access to the tree images, he can only extract information through the teacher. So the student draws some arbitrary images, and the teacher’s role is to punish the student when the drawings don’t look like the images I provided, and to reward the student when they look similar. Meanwhile, I also punish the teacher when they make an incorrect judgement on a student generated image (i.e if they think the student’s drawing is real when it isn’t).
When we look at the distribution of trees, there are distinct classes of trees - trees with needles, leafy trees, and more. Along the way we can imagine the student generating a hybrid oak/pine tree, and our teacher should pick up on this and usher the student to generate images of these disctinct classes in seperate images. Throughout this process the student ends up getting better at generating images, and the teacher gets better at telling the difference between the student’s images and the real ones. These two players are constantly attempting to one-up eachother throughout this process.
Eventually we reach a point where either the student can’t draw better images, or the teacher can’t get better at telling the difference between the student drawings and the real ones. If this push and pull learning experience between the two actors (student and teacher) goes smoothly, it eventually yields a student who is exceptional at drawing realistic trees. The interesting part about this, is that the trees drawn by the student aren’t necessarily real. It’s just a tree that is entirely plausible given the distribution of tree images we provided. Eventually we end up having a student with the ability to synthesize tree images. I now have a tool I can use to generate photo-realistic trees on demand!
We can quanitfy this process with the use of loss functions. Shown below is a typical loss function used in GANs (known as the WGAN loss functions). The goal of the network is to minimize these loss functions in tandem. The top one pertains to the teacher - the teacher obtains samples and provides a score. The loss function for the teacher attempts to maximize the scores on real samples, and minimize the scores on generated (i.e student) samples. Here the D() represents the teacher’s score on a sample - where a larger score indicates a “realer” sample. Meanwhile the student tries to maximize the teacher’s scores on their samples - they want to fool the teacher.
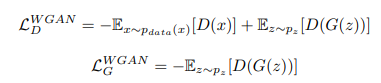
You can see how these two loss functions compete against each other. This isn’t like our typical situation in supervised learning where we can minimize a single loss function. Now we have two competing players, and the optimal situation for these two lies at an intersection between the minimum of LD and the maximum of -LG - i.e the saddle point between these two loss curves. This is also considered the Nash Equilibrium from game theory.
Below is an example of this generative adversarial process applied to dog images. This image was generated by a GAN (from BigGAN), and it is not real. When I say not real, I mean not from the physical world. It is, however, constructed with dog features taken from the physical world. This image was drawn up entirely by the “student” in this BigGAN network, who’s objective in this case was to draw up dogs. The quality of the generated image is amazing, and showcases the exceptional abilities of these networks.
